4.3 Crawl Data, Processed Data, etc.
The system stores crawl data in index-n/storage/, along with processed data and other various long-term data.
The data generated by the system is in general viewable within the control GUI, under Index Nodes -> Node N -> Storage.

Clicking on the paths in this view will bring up details.
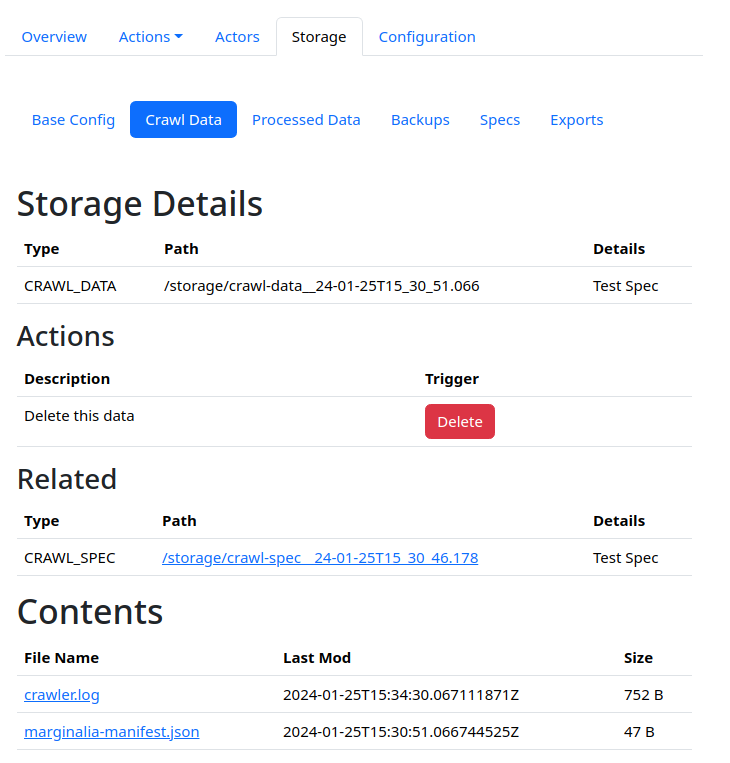
This view will show the path of the data relative to the node storage root (e.g. install-dir/index-1 on disk),
its relation to other data (e.g. crawl data to processed data), and any files in the root directory of the crawl data.
These can be directly downloaded from this view. Note that directories are not shown in this view. This is due to size constraints.
A special file marginalia_manifest.json exists in all storage objects. This enables the system to recover information about
the directory in the event of an irrecoverable database error. It also means if you move crawl data from e.g. index-1 to index-2, then
the system will pick up the change automatically.
In The Filesystem
In general, the names of the storage directories reflect their content. Crawl data is stored in directories with names like crawl_data_...,
and so on.
Crawl Data
In the root of the directory is a file called crawler.log, which is a journal of what has been crawled, and where it is stored.
It will relate domain names to subdirectories.
To get around file system limitations, the crawl data is stored in a subdirectory tree. Each domain is stored in a separate parquet file.
Crawling a sample set of marginalia websites will result in a crawl_data_…-directory with these files:
crawler.log
marginalia-manifest.json
37/0a/370a41de-search.marginalia.nu.parquet
3d/44/3d440131-docs.marginalia.nu.parquet
50/07/50071b16-encyclopedia.marginalia.nu.parquet
69/9b/699b8d-www.marginalia.nu.parquet
76/7a/767a957e-memex.marginalia.nu.parquet
If we inspect the crawler.log file, which acts both as a journal for the crawler, and an index for navigating the data, we find these lines:
# Starting WorkLog @ 2024-02-12T16:38:47.267678766
memex.marginalia.nu 2024-02-12T16:38:48.074759835 /storage/crawl-data__24-02-12T16_38_44.774/76/7a/767a957e-memex.marginalia.nu.parquet 1
encyclopedia.marginalia.nu 2024-02-12T16:38:49.258043503 /storage/crawl-data__24-02-12T16_38_44.774/50/07/50071b16-encyclopedia.marginalia.nu.parquet 1
search.marginalia.nu 2024-02-12T16:38:49.258399009 /storage/crawl-data__24-02-12T16_38_44.774/37/0a/370a41de-search.marginalia.nu.parquet 1
docs.marginalia.nu 2024-02-12T16:39:19.524394369 /storage/crawl-data__24-02-12T16_38_44.774/3d/44/3d440131-docs.marginalia.nu.parquet 31
www.marginalia.nu 2024-02-12T16:42:12.546372348 /storage/crawl-data__24-02-12T16_38_44.774/69/9b/699b8d-www.marginalia.nu.parquet 194
Parquet files can be interrogated with SQL using e.g. duckdb.
Processed Data
Processed data follows an analogous pattern, with the difference that it does not construct a directory hierarchy, but stores its data directly in the root in much fewer files.
processor.log
marginalia-manifest.json
domain0000.parquet
domain-link0000.parquet
document0000.parquet
The processor.log file also has a different pattern, e.g.
# Format:
# + ID signifies adding an item to the current batch
# F signifies finalizing the current batch and switching to the next
# X discard contents from the current batch and start over, written after a crash
# Upon a crash, items that have re-process until their batch is finalized
+ memex.marginalia.nu
+ encyclopedia.marginalia.nu
+ search.marginalia.nu
+ docs.marginalia.nu
+ www.marginalia.nu
# 2024-02-12T16:43:07.789999695
# finalizing batchNumber = 0
F